Quick test to check this publishing route still works.
Author: Jonathan Sanderson
[taps mic] Is this thing on?
Looks like it might be useful again, in the not-too-distant.
Changing the screen brightness on a Pi-Top Ceed
TL;DR:
You need to install OpenCV and its python libraries
Update:
This no longer works. At all.
One aspect of the Raspberry Pi ecosystem which continues to baffle me is the absence of a good cheap Pi desktop system. The Pi400 is terrific, but it lacks a monitor. In fact, monitors are a huge sticking point, in that it’s really hard to buy anything smaller than about 23″ across, and for less than about £120, that doesn’t plain suck. And if I were to buy a bunch of such monitors – where would I put them when they weren’t in use? They’re massive.
As far as I can tell, there’s no reliable supply of, say, 15″ 1080p laptop display panels with neat little stands and HDMI inputs. Doubtless nobody sells them because the economics don’t work out, but this still sucks.
There have been a couple of attempts to fix this, over the years. The Pi folks themselves sell a little 7″ touchscreen, but… well, it was maybe a decent proof of concept, but beyond that it’s pretty hopeless. The only product I’ve seen that makes any sense is Pi-Top’s Ceed unit. I mostly like it: a small footprint on your desk, the Pi’s pins are sort-of accessible if you plug in a slightly odd extra bit (or do what everyone actually does and leave the Pi hanging out), the display is fairly poor but ‘good enough’, and the price is… well, it’s OK. Best of all: it’s lime green.
The units more-or-less stack, too, which makes them fairly easy to stash on a shelf when they’re not in use. You can fit about eight in a standard Tesco bag-for-life, which isn’t exactly great packaging but works pretty well if you’re careful.
Trouble is, the Ceed hasn’t been updated in years. It doesn’t really support the Pi 4 (though I believe you can make it work, if you power it separately), the display panel is still a shaky 1344×768, and so on.
Worst of all, the software support is… well, ‘quirky,’ if I’m being generous. For reasons I’ve never understood, Pi-Top run their own OS distribution. It’s built on top of Raspbian, but they do their own thing for a lot of classroom tools and teaching materials. I’ve zero interest in any of that, not because it isn’t good (I’ve no idea), but because I work across a range of systems and I want my Pis to be as close to vanilla as possible.
So, today: Pi3 on my desk, in a Ceed case. Fresh install of Raspbian on an SD card. Away we go. First problem: the screen’s awfully dim. How do I turn the backlight up?
There used to be a neat little script on github which worked well, but that now points to a help FAQ which doesn’t actually work, and anyway is incomplete. Here’s what actually worked for me:
First up, with the Pi’s pins connected to the Pi-Top Ceed Hub via the chunky cable, you need to enable SPI (or I2C, I forget which. Just turn both on). Do this is Preferences -> Pi Configuration -> Interfaces, then reboot.
Now you need some additional packages installed, but they’re not in the main Raspbian repo. The Knowledgebase article linked above would have you enter:
echo "deb http://apt.pi-top.com/pi-top-os sirius main contrib non-free" | sudo tee /etc/apt/sources.list.d/pi-top.list &> /dev/null
curl https://apt.pi-top.com/pt-apt.asc | sudo apt-key addThe first line here failed for me. I ended up adding the pi-top.list entry to /etc/apt/sources.list.d manually. The second line adding the crypto key worked.
An apt update/upgrade at this point does some slightly weird things, like install a different version of SonicPi. Mmmm. Whatever, but that’s not a great first impression.
The instructions then suggest:
sudo apt install --no-install-recommends pt-device-manager pt-firmware-updater pt-sys-oled
Meh, whatever. The oled thing is presumably to do with the fancier pi-top modular products, I’m not sure how it’s relevant here. Not installing recommended packages seems odd, and I eventually re-installed pt-device-manager without that flag. I’ve no idea if that was critical or not.
…and that’s where the knowledgebase article stops. After a bunch of digging around, I learned that the new command-line tool is ‘pi-top’, and that I was looking to do something like:
pi-top display brightness 10…which sounds great. But it doesn’t work, because the python script underpinning the pi-top command has a dependency on … er … OpenCV.
I’m sorry, let me check my notes. Yes, ModuleNotFoundError: No module named 'cv2'.
<blinks>
The screen brightness control requires 280Mb of vision processing library?
Right.
Well,
sudo apt install python3-opencv…and now the brightness command works. It takes about ten seconds to run, but it works.
Anyway, the upshot is that I’m genuinely not sure I could recommend the Pi-Top Ceed to anyone at this point. I got burned by Pi-Top’s original laptop units – they were shaky, and the support was useless. So I’m still not convinced the company has the resources to properly support legacy products, and a monitor which requires software updates just for a brightness control strikes me as very likely to have issues in the future.
Please, somebody make a ~15″ desktop HDMI monitor for bare Pis and Pi 400s.
Update, 2022-12-05:
As far as I can tell, none of this work any more. Or at least, not on a 64-bit install. The relevant packages appear to be unmaintained, and as far as I can tell the Ceed is now effectively unsupported. Drat.
Packaging a Python guizero app with PyInstaller
TL;DR: Yes, you can, and yes, it ‘just works.’
Longer answer:
This week I realised I needed a small piece of tooling for some of my collaborators on an IoT project. I’ve been running debug and test stuff using Mosquitto‘s handy mosquitto_sub and mosquitto_pub command-line tools, but it’s not exactly reasonable for me to inflict those on others.
So I reached for JavaScript and started whipping up a quick little web app. I thought it’d make a nice change to stumble around committing travesties in a language that wasn’t C++, for a change. Alas, configuration and implementation details made that less straightforward than I’d hoped, so I ended up bailing and reaching for Python. Meh, sometimes you have to know when to quit.
I’ve used Laura Sach and Martin O’Hanlon‘s guizero library a few times before and rather liked it – it’s a minimal-configuration layer on top of… actually, I’m not sure if it’s Qt or Tkinter or what, but that’s rather the point. A few lines of code and you have a basic GUI working, call it done and move on with your life. And I’ve used the Paho MQTT libraries in Python before, so that bit was comfortable. Or so I thought.
Let’s take a look at what I built, some of the mistakes I made along the way, and how I fixed or worked around the problems I encountered.
Pretty quickly I had something like:
import paho.mqtt.client as mqtt
from guizero import App, TextBox
import config
def on_connect(client, userdata, flags, rc):
client.subscribe("#")
def on_message(client, userdata, msg):
payload = str(msg.payload.decode("utf-8"))
mqttMessageBox.append(payload)
def mqttLoop():
client.loop()
client = mqtt.Client()
client.on_connect = on_connect
client.on_message = on_message
client.username_pw_set(config.mqttUsername, config.mqttPassword)
client.connect(config.mqttHostname, config.mqttPort, 60)
app = App(title="My App Name")
mqttMessageBox = TextBox(app, width='fill', height='fill', multiline=True, scrollbar=True, text="Starting up...")
app.repeat(100, mqttLoop)
app.display()Most of this will look familiar if you’ve done a guizero tutorial. The mundane bits are:
- This basic app presents a window with a TextBox object, which it populates with messages received from an MQTT server.
- I’ve omitted a bunch of stuff for clarity: my app has buttons for sending messages as well as the receiving pane.
- The MQTT connection details are in a config.py file, which is listed in my
.gitignore, so I don’t accidentally commit my security credentials to a public repository. Again. - We make an MQTT object
client, then a guizero application and window,app. - Line 9 is needed because pretty much all the example MQTT code out there assumes Python 2.x and fails to mention that the returned message is a byte string, not a (unicode) Python string. So when you output it in Python3, you get something like
b'The string you expect'. This little dance avoids that. Sigh.
Where it gets a little interesting is in the event and loop handling. Paho/MQTT example code typically calls client.loop_forever(), which in this case would conflict with guizero’s model, where the app.display() line also loops forever.
Line 24 is guizero’s way of dealing with this: we register a repeating callback on a guizero object (in this case the App itself, though it could be a widget like the TextBox). Every 100 milliseconds that calls my mqttLoop() function, which in turn calls client.loop(). Done.
guizero/MQTT update loop collisions
…and that works. Sort-of. Turns out something really quite nasty happens with all the looping, and guizero’s window becomes only sporadically responsive. The TextBox tended to update every few seconds at best, or perhaps only when I dragged the window between monitors. Button controls added to the window worked, sort-of, but were somewhat unresponsive and didn’t visually register clicks.
Upping the repeat time (ie. app.repeat(1000, mqttLoop)) helped the window, but the MQTT handling became janky. I fiddled for a while but a looming sense of ‘this isn’t going to work’ forced a rethink.
The fix turns out to be obvious in the Paho library: forget my mqttLoop() function and replace the guizero repeat line with:
client.loop_start()Paho integrates some sort of threading model, and its updates and callbacks then run independently of whatever guizero is doing. It all just works, and the app behaves smoothly. As you’d expect, only… somehow, not how I’d expected: these are highly abstracted libraries, designed for ease of use in simplistic circumstances, and they’re both working around what as far as I’m aware is still a single-threaded runtime model in Python. And it works. Cool.
A few minutes later I had something a little more fully-featured, which allows my colleagues to send test messages across the device network, and to inspect what the network messaging is doing:
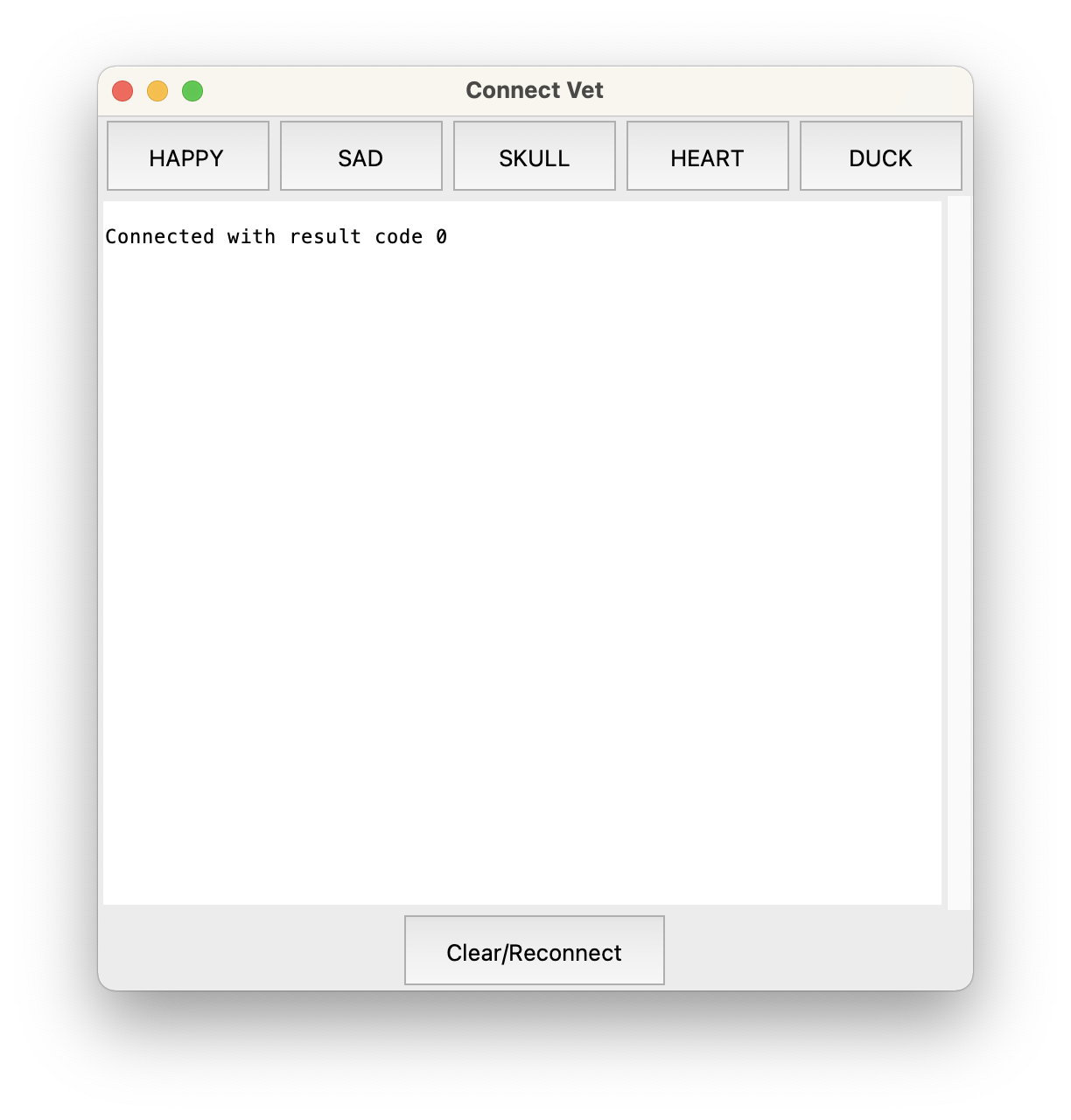
I really do mean ‘a few minutes’ – I’m working in VS Code with the beta of GitHub Copilot, and it’s flat-out amazing in terms of suggesting whole blocks of code for you. Often from the example or tutorial you’re following along with, which is a bit spooky.
Anyway, let me be clear that this app is not going to win any Apple Design Awards. But hey, it’s utility tooling for internal use. I need it soon, cross-platform, and ‘good enough’. The above is good enough.
Autoscrolling TextBox in guizero
I had two issues remaining. One was that the messages scroll off the bottom of the TextBox, the fix for which is in a comment on this Stack Overflow query. After line 10 above, add:
mqttMessageBox.tk.see('end')We’re reaching through guizero to the underlying GUI library here (ah, look – it’s Tkinter after all!), and prompting it to scroll down. The API call seems weird, but it works so let’s gloss over that and move on.
Packaging (PyInstaller)
The last remaining issue: how do I give people this app? I can’t very well ask them to navigate to the right directory in a shell and type python3 vet.py every time.
The solution I’ve wanted an excuse to play with for a while is PyInstaller. One thing which has occasionally put me off is that the ‘Quickstart’ docs say:
pip install pyinstaller
pyinstaller yourprogram.py…and that’s it. Which seems implausible to the point of being ridiculous.
Except: that pretty much was it, for me. Some minor notes:
- For
pipreadpip3. One underlying theme you might spot in this post is that we are not yet done with the Python3 transition. Oooooh, no. - I’m not sure where PyQt comes into this, but it does… and for a while at the start of the year PyQt was one of those things that really didn’t play nicely with the new-fangled Apple Silicon Macs. Like, er, the one I’m working on. Those messy days are happily behind us, but I had to debug some legacy cruft in my system. That pretty much boiled down to
brew link pyqt@5after I’d removed an old shared library object that was still lying around – brew told me what to do when I triedbrew install pyqt@5. - To make an executable application package, the incantation you need is
pyinstaller --windowed yourprogram.py.
Now, PyInstaller isn’t perfect. I’d need to jump through some hoops if I wanted to sign the Mac app, but more importantly it’s not a cross-compiler: to package for Windows, you need to run it on Windows. And then there are, well, complications. I’ll try that tomorrow, maybe.
Wrapping up
The big take-home for me is this: being able to build bespoke bits of tooling is extremely helpful, and the faffing time involved in getting something like this out of the door is really very short. It’s genuinely taken me longer to write this post. You do need to be aware of what a fairly large range of moving parts are called, but once you can name things you can google them, and the chances are really very good that they’ll play nicely together.
The biggest challenge I typically come across is that gap between the trivial-case ‘quick start’ sort of guide, and the full-on API docs. This is where Stack Overflow is useful, but test cases there tend to be so specific it can be challenging to find the right one which relates to your code, or to find anything at all if you’re not sure where to start.
I suspect I’m far from alone in being broadly marginally competent, but still finding API docs hard to read. What’s lacking, I think, is intermediate-level worked examples. Hence this blog post, even if it boils down to ‘Packaging guizero with PyInstaller: yes, that works.’
If you’d like to see the code for the ‘full’ app – such as it is – it’s in this GitHub repository. It’s also worth checking out Laura and Martin’s recent guizero book, which is a fine example of… oh, intermediate-level worked examples. Well, fancy that.
Update 2021-09-03: Windows 10 package
Turned out I didn’t even have Python installed on my Windows box, so that was fun (hurray for Chocolatey, for that). Then I had some fumbling around with PowerShell, because I’m really not familiar with the Windows command line. I keep Git Bash around because while it’s weird and rather slow, if I squint a little it’s more familiar for me than anything PowerShell does. I’ve pretty much zero interest in learning Windows admin stuff at this point.
Finally, I had some dancing around to do to find the correct incantation to build my executable package. For a while I was doing the right thing, but something in the vet.spec file PyInstaller generates was forcing the wrong thing. Deleting the build and dist directories and the .spec file, then re-running pyinstaller vet.py -w --onefile produced what I want, which is a single .exe file I can bung on a file share and invite project collaborators to download and run.
It works! It’s even uglier than the Mac version, but it works and it’s mine. I’ll need to repeat the dance on a Raspberry Pi at some point, but for now: utility done, on with the next task.
Coda: somewhat astonishingly, the Windows .exe (built on a 12 year-old Mac Pro, seriously) also works on Windows 11 in emulation under arm64, as virtualised on my ARM MacBook. So many people in so many places working so hard, so muppets like me can build things that… ‘just work.’ Maybe the world can be a better place after all?
Teams
If you know, you know.
My theory: the design brief was: “Build something which looks like Slack and demos well enough, but that is quantifiably worse in every respect. Then add video chat, because we have that lying around and it’s the one thing Slack doesn’t have, so everyone will have to choose us anyway.”
My laundry list from today:
- Make the top-level organisational concept (the ‘Team’) a second-level component of the user interface, so you can’t switch quickly between Teams. cf. Slack’s ⌘1, ⌘2 etc.
- Remove notifications from the interface for tertiary-level elements. So to find out if you have new messages within a specific team’s group, you have to open that team.
- Ensure all of this is slow.
- No keyboard shortcuts for any of this.
- No menu items for any of this.
- No matter how many Teams you’re a part of, they’re all presented within precisely one window.
- Except Chats, which can be split out into separate windows.
- …from which key elements of the interface are removed.
- …except on mobile, where the ‘reply to specific message’ feature is added.
- …so on mobile, drop the partial Markdown-processing of text entry.
- Ignore separate Chat windows and switch to the main viewer if you respond to a notification alert.
- Make those notification alerts not use system-provided mechanisms.
Let’s not get started on why Immersive Reader is a top-level right-click action for individual messages.
The irony here is that email bloody sucks, and many of us have been arguing to get off it for years. What I hadn’t anticipated was the future where we actually do move away from email… to something worse.
Back in the Pro Game
This guide to upgrading classic ‘cheesegrater’ Mac Pros is a rare example of a document which earns its ‘definitive’ title. An astonishing and immensely valuable piece of work.
Related: I’m dusting off my old Mac Pro. Again. It was built in 2008 – twelve years ago – but it’s enough of a tank that I fear it will once again be pressed into service. In theory I can hack it to run the current Mac OS, though it’s not quite clear if it’s going to need yet another graphics card to manage that. If all else fails I can reboot it into (whisper it) Windows 10, where it seems to behave like a normal, supported system.
Not being able to upgrade the RAM and drive in my not-quite-as-old MacBook Pro means it’s not cutting the workloads I’m trying to hack on right now. Amusingly enough, what’s tipped it over the edge is … Microsoft Teams. Sigh.
Where the time goes
One sign of a large project can be the degree of arcane hoop-jumping foisted on project members. Right now, I’ve a few projects underway where I’m supposed to track my time. In at least one case, the overhead of tracking my time will amount to more of my time than the time on the project I’m tracking. If you see what I mean. But here we are.
For the most part I’m rather enjoying using Toggl, which syncs nicely between web, desktop and mobile apps. It also nags me quite successfully, without being too smug about it. However, entering data is a little clunkier than I’d like, and the visual design and typography feel to me just a little… off, somehow. Like the app should be doing just a little more to render my recent history clearly? I’m not sure.
I’ll very likely stick with Toggl, but Brett Terpstra’s command-line/plain text system doing has caught my attention. I’m working partly on an Ubuntu laptop these days (more about that another time, perhaps, but the short version is: meh, but it was cheap) and tearing core tools out of the Mac/iOS ecosystem has its attractions. Presumably I could stick a doing log file in Dropbox and access it from whatever system I happen to be in front of, but these sorts of shell tools aren’t very usable from my phone, so there’s little net benefit right now. This is also why I haven’t (yet?) moved from Things to something more like .taskpaper format files. Also because Things is delightful and fabulous and sync works in exactly the way Dropbox sync all too often doesn’t.
Still: doing: interesting.
I get paid to do this
Duds
In lieu of writing anything new here, I’ve switched up the theme again.
Munchie box
Instantly realised my whole “rediscovering my Scottish roots” thing was just a pretension, and that actually I’m just a dickhead who travelled 700 miles for a takeaway.
Writing for Vice, Tom Usher tackles a Glaswegian munchie box. Epic, and great writing deployed in honour of a worthy cause.